Tutoriel 1 (FR): Exécuter un cas test PyWaPOR dans Colab
3. Exécuter un cas test PyWaPOR dans Jupyter Notebook
Dans cette étape, vous allez créer de nouvelles cellules de code qui exécutent chaque étape de pyWaPOR. Pour le cas d’étude, nous avons sélectionné la zone de Wad Helal, que vous devriez connaître grâce au MOOC. Dans cet exercice, le code pour exécuter ce cas test est écrit. Vous pouvez copier le code de chaque étape, le coller dans une nouvelle cellule de code et l'exécuter.
Pour chaque élément numéroté ci-dessous, créez une nouvelle cellule de code dans JupyterLab (raccourci : B), copiez le code dans la cellule et exécutez-le (raccourci : SHIFT + ENTER).
!pip install pywapor
import pywapor
- Ce code importera le package pywapor dans le noyau Python actuel.
2. Configurer le projet pour le cas test
project_folder = r"Test_case" #Path to folder bb = [33.1479429498060583, 14.2657100971198449, 33.2874918465625242, 14.3487734799492763] # [xmin, ymin, xmax, ymax] #Wad_Helal period = ["2023-03-01", "2023-03-02"] # Set up a project. project = pywapor.Project(project_folder, bb, period)
- Ce code crée un nouveau dossier de projet pour le cas test, nommé "Test_case", définit le cadre géographique (longitude minimale, latitude minimale, longitude maximale, latitude maximale) du cas test (c'est-à-dire, Wad Helal), et définit la période de temps que le modèle va exécuter. Pour ce cas, nous allons exécuter le modèle pour seulement 2 jours à titre d'exemple (c'est-à-dire les deux premiers jours de mars 2023).
3. Configurer l'ensemble de données d'entrée
summary = { '_ENHANCE_': {"lst": ["pywapor.enhancers.dms.thermal_sharpener.sharpen"],}, '_EXAMPLE_': 'SENTINEL2.S2MSI2A_R20m', '_WHITTAKER_': {'SENTINEL2.S2MSI2A_R20m':{'method':'linear'}, 'VIIRSL1.VNP02IMG':{'method':'linear'}, }, 'elevation': {'COPERNICUS.GLO30'}, 'meteorological': {'GEOS5.inst3_2d_asm_Nx'}, 'optical': {'SENTINEL2.S2MSI2A_R20m'}, 'precipitation': {'CHIRPS.P05'}, 'soil moisture': {'FILE:{folder}{sep}se_root_out*.nc'}, 'solar radiation': {'MERRA2.M2T1NXRAD.5.12.4'}, 'statics': {'STATICS.WaPOR3'}, 'thermal': {'VIIRSL1.VNP02IMG'}, } project.load_configuration(summary = summary)
- Ce code configure les ensembles de données d'entrée pour ce projet test. Toutes les informations sur les sources des ensembles de données d'entrée et les méthodes pour prétraiter les données sont définies par la variable 'summary'. Il existe également des options pour exécuter pywapor avec l'ensemble d'entrées par défaut utilisé pour les produits de données WaPOR. En cours, vous apprendrez plus sur les différentes configurations par défaut et personnalisées de pywapor et ce que chaque ligne de ce code signifie.
4. Configurer les identifiants pour télécharger les données
project.set_passwords()
- Ce code vous demandera de saisir les identifiants et mots de passe requis pour télécharger les ensembles de données d'entrée configurés. Utilisez le compte utilisateur et le mot de passe que vous avez créés dans l'étape précédente :
Créer des comptes utilisateurs
- . Pour ce cas test, vous devrez entrer le nom d'utilisateur et le mot de passe du compte
NASA Earthdata
- , ainsi que l'adresse e-mail et le mot de passe du compte
Copernicus
- . D'autres comptes sont utilisés lorsque vous souhaitez exécuter pywapor avec d'autres ensembles de données.
5. Télécharger les données
datasets = project.download_data()
Ce code démarrera le processus de téléchargement des données d'entrée pour pywapor. Lorsque le noyau Python exécute la cellule, assurez-vous d'avoir une connexion internet. Le temps de téléchargement des données dépend de la période et de la zone, ainsi que de la connexion internet (une indication est que pour la zone de Wad Helal, cela prend moins de 30 minutes pour télécharger les données de 2 jours).
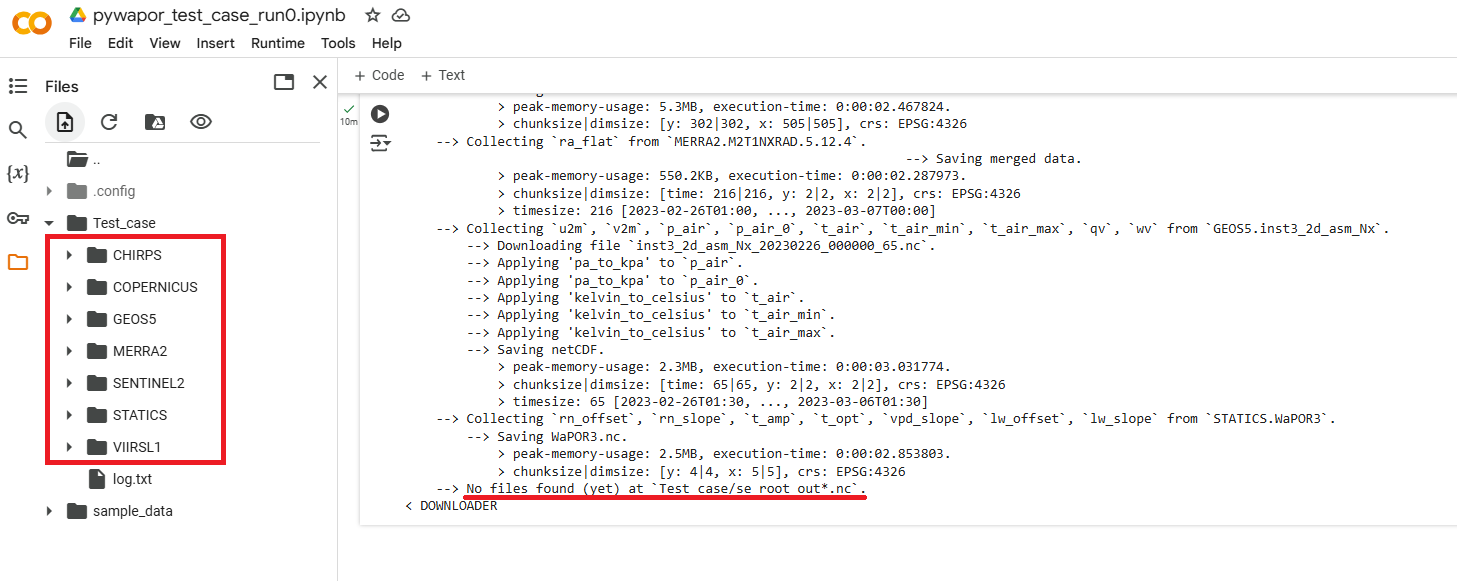
Après cette étape, si toutes les données sont téléchargées avec succès, vous devriez trouver ces dossiers d'entrée dans le panneau Fichiers sur la gauche (pour ouvrir ce panneau, cliquez sur l'icône du dossier ![]() ) :
) :
Remarque :
- Il n'est pas nécessaire de télécharger le fichier se_root_out*.nc à cette étape, car nous utilisons un modèle pour calculer l'humidité du sol dans la zone racinaire. Par conséquent, vous pouvez ignorer l'avertissement « Aucun fichier n'a été trouvé (pour l'instant) dans 'Test_case/se_root_out*.nc' ».
- Si un autre fichier n'a pas été trouvé ou si des messages d'erreur s'affichent à cette étape, cela signifie que les entrées requises n'ont pas été complètement téléchargées (en raison d'erreurs de connexion ou de serveur). Vous devrez réexécuter cette cellule.
6. Exécuter le modèle d'humidité du sol dans la zone racinaire
se_root_in = project.run_pre_se_root() se_root = project.run_se_root()
- Ce code exécutera le module se_root pour calculer l'humidité du sol dans la zone racinaire, ce qui est une entrée pour calculer l'évapotranspiration
7. Exécuter le modèle etlook
et_look_in = project.run_pre_et_look() et_look = project.run_et_look()
Lors de l'exécution de chaque cellule, observez les sorties affichées.
À la fin de cet exercice, vous devriez être en mesure de créer un notebook Jupyter comme cet exemple de notebook, d'exécuter ce notebook et d'obtenir le fichier de sortie pywapor et_look_out.nc. Ensuite, nous examinerons ce fichier de sortie et en discuterons en classe.