Tutoriel 3 (FR): Configurer pyWaPOR pour votre propre étude de cas
| Site: | IHE DELFT OPENCOURSEWARE |
| Course: | PyWaPOR OpenCourseWare |
| Book: | Tutoriel 3 (FR): Configurer pyWaPOR pour votre propre étude de cas |
| Printed by: | Guest user |
| Date: | Friday, 26 December 2025, 6:53 PM |
Description
Dans ce tutoriel, vous allez créer un Jupyter Notebook pour exécuter pyWaPOR sur votre propre étude de cas, sur votre ordinateur local. Similaire à l'exemple de test, ce notebook devra contenir toutes les cellules de code nécessaires pour configurer le projet, configurer l'ensemble de données d'entrée, paramétrer les comptes, télécharger les données, exécuter le modèle d'humidité du sol de la zone racinaire (SERoot) et exécuter le modèle ETLook. Cependant, la différence ici est que vous allez créer et exécuter ce notebook sur votre ordinateur local.
1. Créer un nouveau notebook pour votre projet
Après avoir créé un environnement python avec pywapor et jupyterlab en suivant les étapes du Tutoriel 2 : Installation de Jupyter Notebook sur votre ordinateur local, vous pouvez maintenant ouvrir JupyterLab sur votre PC. Dans cette étape, vous allez créer un nouveau jupyter notebook pour votre propre cas d'étude :
- Commencez par ouvrir Miniforge Prompt et exécutez cette ligne de commande
mamba activate pywapor_env
- Ensuite, changez de dossier de travail. Nous vous recommandons vivement de créer un dossier dédié pour chaque nouveau projet sur un disque où vous disposez de suffisamment d'espace de stockage disponible (par exemple, D:\pywapor). Si vous êtes sur le lecteur C:, vous devrez d'abord passer au lecteur D: en utilisant la commande ci-dessous:
D:
cd D:\\pywapor
- Exécutez la commande ci-dessous pour démarrer JupyterLab
jupyter lab
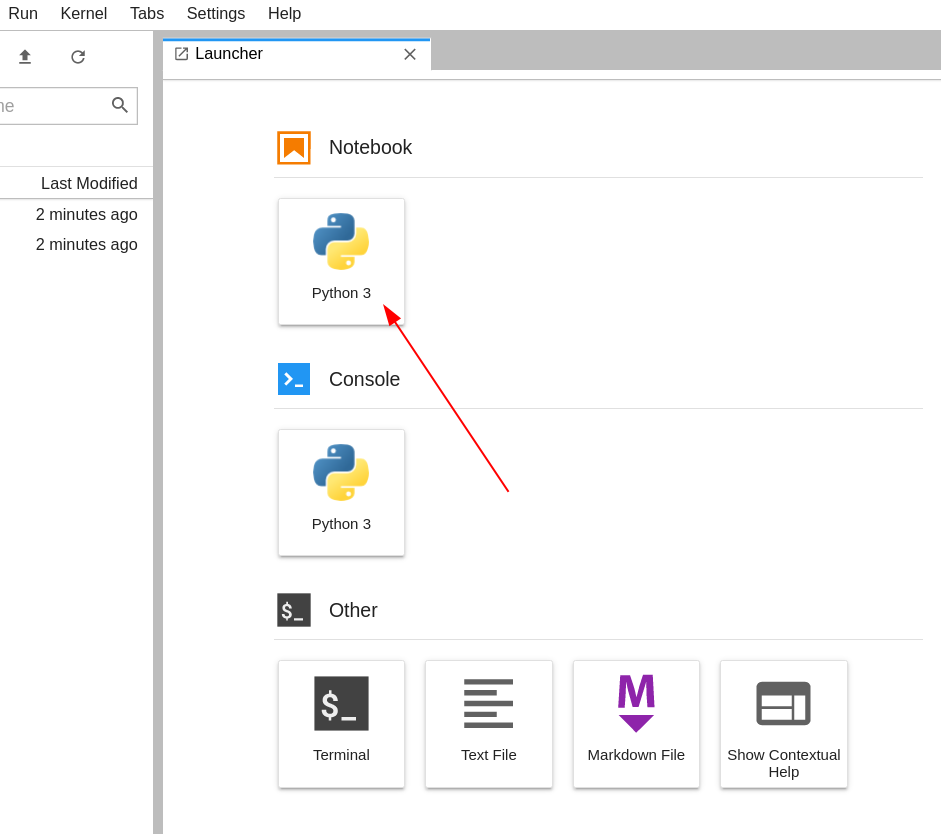
Une fois l'interface JupyterLab ouverte dans votre navigateur web, cliquez sur la tuile "Python" sous "Notebook" dans l'onglet "Launcher" pour créer un nouveau notebook.
(© Copyright CodeRefinery team)
Vous verrez un nouveau notebook nommé "Untitled.ipynb". Pour changer le nom du notebook, faites un clic droit sur l'onglet et sélectionnez "Renommer le notebook...".
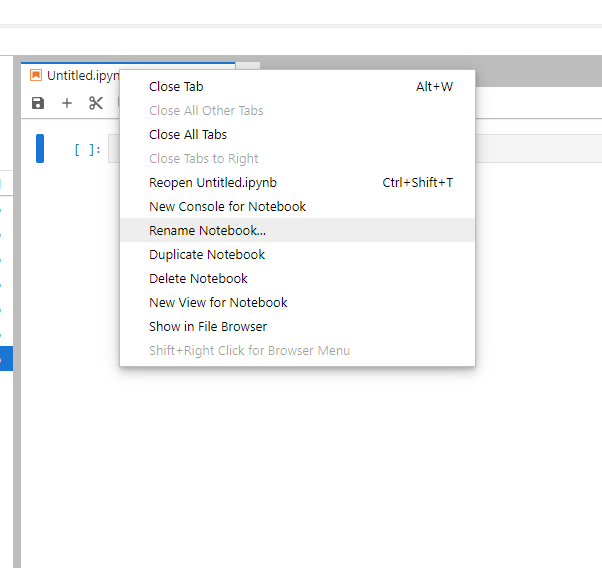
Entrez le nom de ce nouveau notebook (par exemple, "Run pywapor case study.ipynb") et cliquez sur "Renommer".
Dans la première cellule de code, importez le package pywapor en exécutant ce code :
import pywapor
2. Configuration de PyWaPOR
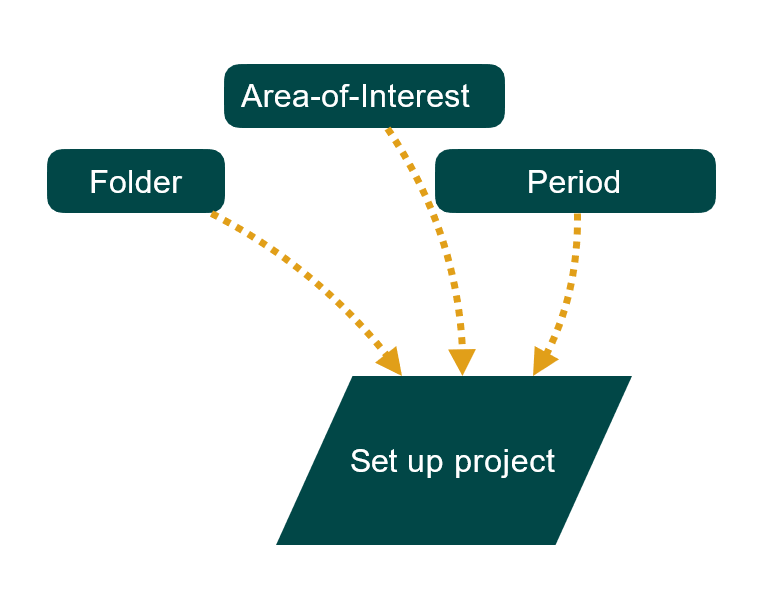
Pour configurer PyWaPOR pour votre propre cas d'étude, vous devez disposer des informations suivantes pour configurer le système :
- Dossier de sauvegarde du project
- Les limites de la zone d'étude (Area of Interest)
- Le début et la fin de la saison de culture
Créez une nouvelle cellule de code avec les paramètres de votre nouveau projet en utilisant ce modèle :
project_folder = r"D:\\pywapor\\Case_study" #Path to folder bb = [xmin, ymin, xmax, ymax] #Bounding box of your area period = ["YYYY-MM-DD", "YYYY-MM-DD"] # Set up a project. project = pywapor.Project(project_folder, bb, period)
2.1. Dossier
Remplacez la valeur de project_folder dans le code ci-dessus par le chemin d'accès absolu de votre dossier de projet. Comme vous avez démarré Jupyter Notebook dans votre dossier de travail (par exemple, D:\pywapor), si vous utilisez un chemin relatif (par exemple "Case_study" au lieu de "D:\Case_study"), la fonction pywapor.Project créera un nouveau dossier dans votre dossier de travail nommé "Case_study" (par exemple, D:\pywapor\Case_study).
Remarques
- Lors de la modification de la zone d'étude, de la période ou de la configuration du projet, il est préférable de créer un dossier de projet distinct.
2.2. Zone d'étude
Remplacez la valeur de bb dans le code modèle ci-dessus par une liste des longitudes et latitudes minimales et maximales de votre zone d'étude. Si vous avez un fichier shapefile de votre zone d'étude (avec le système de référence de coordonnées EPSG:4326), la boîte englobante de votre zone d'étude peut être trouvée à partir de l'étendue du shapefile. Ouvrez le shapefile dans QGIS. Ensuite, faites un clic droit sur la couche shapefile dans le panneau des couches et sélectionnez "Propriétés". Dans l'onglet "Informations", copiez les coordonnées de l' "Étendue". Voir l'exemple ci-dessous.
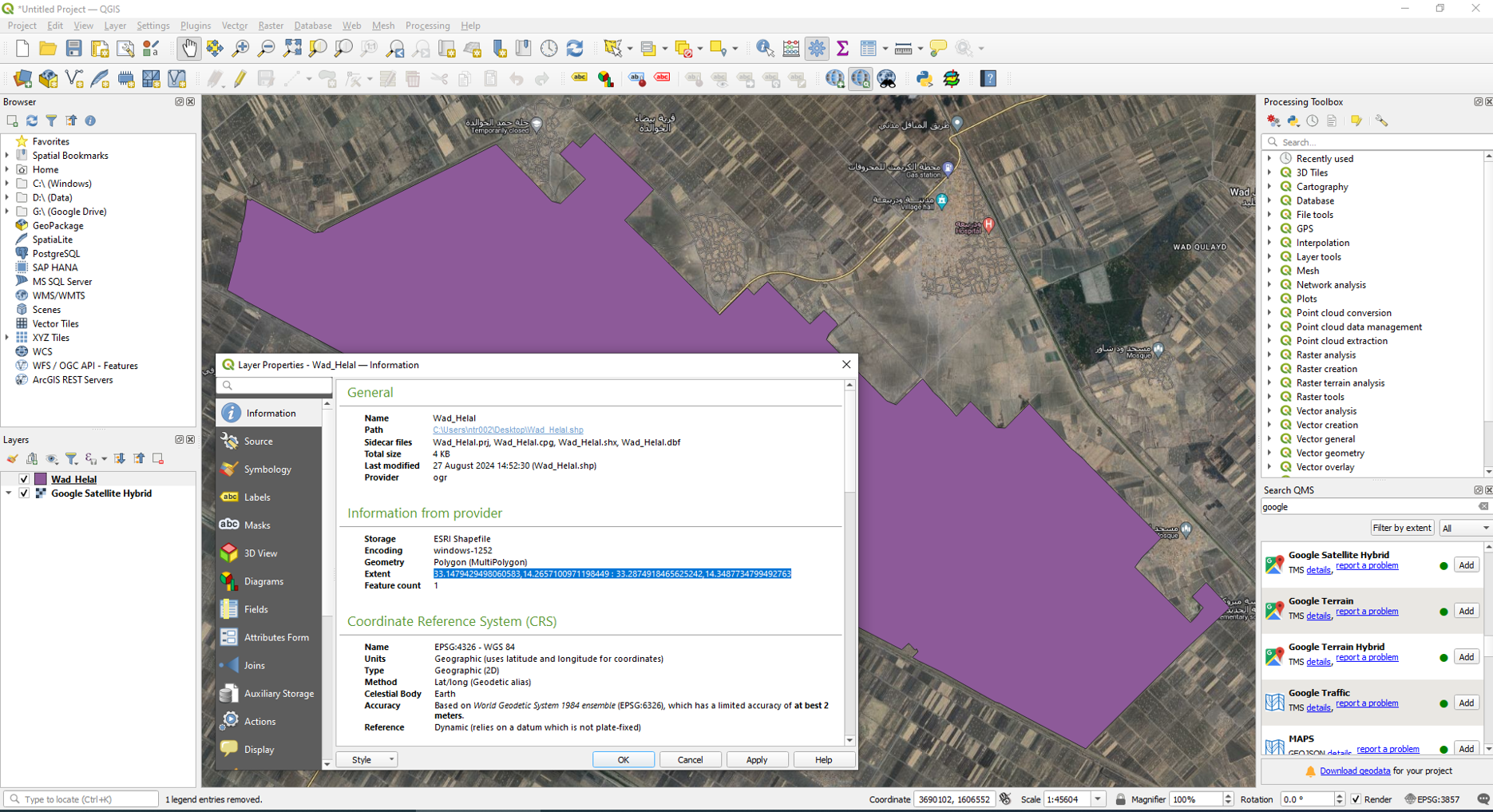
Collez les coordonnées copiées dans la cellule de code de Jupyter Notebook, puis reformatez depuis xmin, ymin: xmax, ymax pour obtenir [xmin, ymin, xmax, ymax].
2.3. Période
Remplacez la valeur de period dans le code modèle ci-dessus par une liste de la date de début et de la date de fin de votre période d'étude au format ["AAAA-MM-JJ", "AAAA-MM-JJ"].
En fonction de la taille de votre zone d'étude et de la capacité de votre ordinateur, une longue période (de quelques mois à plus d'un an) pourrait surcharger la mémoire de traitement de votre ordinateur. Comme nous exécutons le script sur un ordinateur portable standard (8 Go de RAM), nous ne pouvons télécharger et traiter qu'un mois de données. Sélectionnez un mois au milieu de votre saison de culture et ajoutez 5 jours avant et après pour avoir une période tampon pour l'interpolation des dates avec des données manquantes.
Par exemple, si votre saison de culture est du 01/10/2020 au 30/04/2021, sélectionnez le mois central du 01/01/2021 au 31/01/2021. Ensuite, ajoutez 5 jours avant et après cette période. La valeur de period devrait donc être ["2020-12-25", "2021-02-05"].
Après avoir rempli la cellule de code de configuration du projet avec les informations requises de votre projet, exécutez la cellule de code.
3. Télécharger les données d'entrée
Après avoir configuré le projet, l'étape suivante consiste à configurer l'ensemble de données d'entrée et à télécharger les données. Copiez le code ci-dessous dans votre notebook et exécutez les cellules de code.
- Configurer l'ensemble de données d'entrée
summary = { 'elevation': {'COPERNICUS.GLO30'}, 'meteorological': {'GEOS5.inst3_2d_asm_Nx'}, 'optical': {'SENTINEL2.S2MSI2A_R20m'}, 'precipitation': {'CHIRPS.P05'}, 'solar radiation': {'MERRA2.M2T1NXRAD.5.12.4'},
'statics': {'STATICS.WaPOR3'}, 'thermal': {'VIIRSL1.VNP02IMG'},
'soil moisture': {'FILE:{folder}{sep}se_root_out*.nc'},
'_ENHANCE_': {"bt": ["pywapor.enhancers.dms.thermal_sharpener.sharpen"],}, '_EXAMPLE_': 'SENTINEL2.S2MSI2A_R20m', '_WHITTAKER_': {'SENTINEL2.S2MSI2A_R20m':{'method':'linear'}, 'VIIRSL1.VNP02IMG':{'method':'linear'}, }, } project.load_configuration(summary = summary)
Vous pouvez configurer un ensemble personnalisé de sources de données d'entrée. Sélectionnez dans ce cas la source et le produit depuis ce lien.
Assurez-vous de remplir toutes les catégories (c'est-à-dire élévation, météorologique, optique, précipitation, rayonnement solaire, statistiques et thermique). Pour la catégorie "humidité du sol", nous utiliserons la sortie du modèle SERoot. Vous pouvez sélectionner plus d'une source de données d'entrée. Si c'est le cas, le téléchargement et le traitement des données prendront plus de temps.
- par exemple si vous voulez utiliser MODIS au lieu de VIIRS pour les données thermales, vous pouvez ajuster l'exemple ci-dessus ainsi:
-
summary = { 'elevation': {'COPERNICUS.GLO30'}, 'meteorological': {'GEOS5.inst3_2d_asm_Nx'}, 'optical': {'SENTINEL2.S2MSI2A_R20m'}, 'precipitation': {'CHIRPS.P05'}, 'solar radiation': {'MERRA2.M2T1NXRAD.5.12.4'},
'statics': {'STATICS.WaPOR3'}, 'thermal': {'MODIS.MYD11A1.061','MODIS.MOD11A1.061'}
'soil moisture': {'FILE:{folder}{sep}se_root_out*.nc'},
'_ENHANCE_': {"lst": ["pywapor.enhancers.dms.thermal_sharpener.sharpen"],}, '_EXAMPLE_': 'SENTINEL2.S2MSI2A_R20m', '_WHITTAKER_': {'SENTINEL2.S2MSI2A_R20m':{'method':'linear'}, 'MODIS.MYD11A1.061':{'method':'linear'},
'MODIS.MOD11A1.061':{'method':'linear'}, }, } project.load_configuration(summary = summary)
-
- Configurer les informations de compte pour télécharger les données
project.set_passwords()
En fonction de la source de données et du produit sélectionnés, le code vous demandera de renseigner les comptes utilisateurs et les mots de passe nécessaires pour télécharger les ensembles de données d'entrée configurés.
- Télécharger les données
datasets = project.download_data()
Ce code lancera le processus de téléchargement des données d'entrée pour pyWaPOR. Lorsque le noyau Python exécute la cellule, assurez-vous d'avoir une connexion internet.
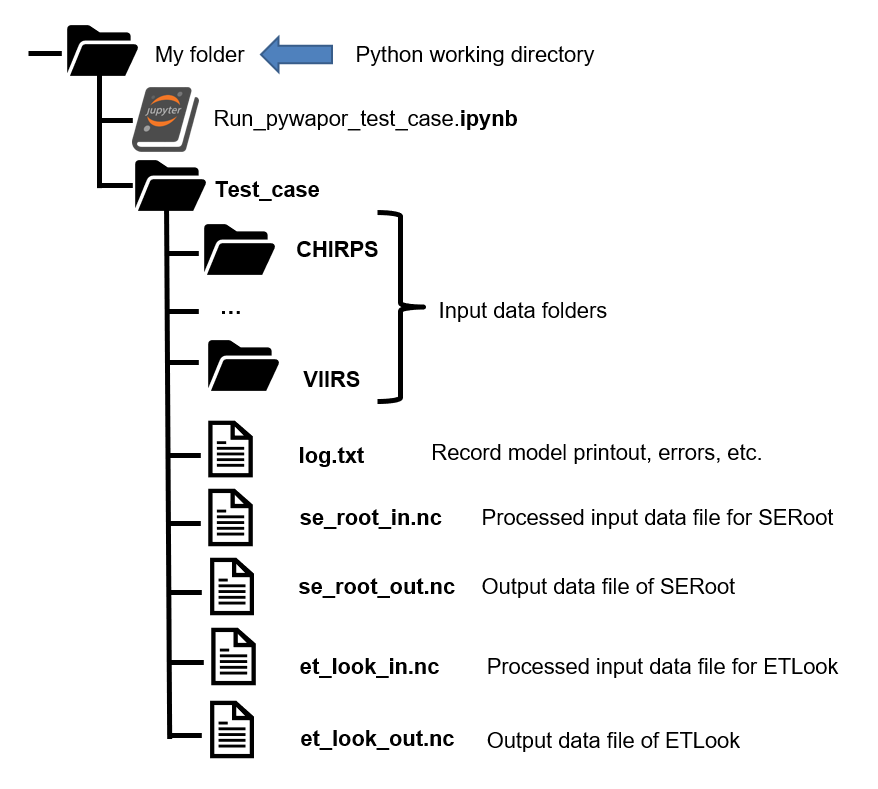
Lors de l'exécution de pyWaPOR pour votre propre étude de cas, l'étape de téléchargement pourrait prendre plus de temps en raison d'interruptions de serveur ou d'autres problèmes. Consultez le journal de téléchargement pour vérifier s'il y a des avertissements indiquant que certaines données d'entrée n'ont pas été complètement téléchargées. Si l'étape de téléchargement est terminée sans avertissements (entre > DOWNLOADER et < DOWNLOADER), cela signifie que toutes les données ont été correctement téléchargées, à l'exception du fichier manquant se_root_out.nc, qui sera créé à l'étape suivante.
Remarques :
En raison d'interruptions de serveur et de connexion internet, vous pourriez voir des avertissements dans le journal indiquant que pyWaPOR continue sans certaines données d'entrée. Si cela se produit, vous devrez relancer l'étape de téléchargement. Pour cela, redémarrez le noyau en sélectionnant l'onglet 'Kernel' > 'Restart Kernel'. Supprimez les fichiers corrompus dans les dossiers de données d'entrée, puis exécutez à nouveau toutes les cellules de code.
4. Exécuter les modèles SERoot et ETLook
Une fois toutes les données collectées avec succès, la seule donnée d'entrée manquante est l'humidité du sol dans la zone racinaire. Copiez le code ci-dessous dans votre notebook et exécutez les cellules de code.
- Exécuter le modèle d'humidité du sol de la zone racinaire
se_root_in = project.run_pre_se_root() se_root = project.run_se_root(chunks = {"time": 1, "x": 500, "y": 500})
Ce code pré-traitera les données
d'entrée et exécutera le module se_root pour calculer l'humidité du sol dans la zone racinaire, qui est une entrée
nécessaire pour calculer l'évapotranspiration.
- Exécuter le modèle ETLook
et_look_in = project.run_pre_et_look() et_look = project.run_et_look(chunks = {"time_bins": 1, "x": 500, "y": 500})
Ce code pré-traitera les données
d'entrée et exécutera le module et_look pour calculer l'évaporation, la transpiration, l'interception et la
production primaire nette.
Lors de l'exécution de chaque
cellule, observez les messages imprimés dans les sorties. À la fin de cet
exercice, vous devriez avoir le fichier de sortie et_look_out.nc parmi d'autres fichiers dans le dossier du
projet: