Tutorial 1 (ES): Ejecución de pyWaPOR para casos de prueba en Google Colab
| Site: | IHE DELFT OPENCOURSEWARE |
| Course: | PyWaPOR OpenCourseWare |
| Book: | Tutorial 1 (ES): Ejecución de pyWaPOR para casos de prueba en Google Colab |
| Printed by: | Guest user |
| Date: | Friday, 26 December 2025, 6:53 PM |
Description
Las instrucciones proporcionadas aquí le ayudarán a configurar pyWaPOR para un caso de prueba usando Colab, a ejecutar el caso de prueba y a explorar el archivo de salida.
1. Crear cuentas de usuario
Para acceder a algunos de los datos de entrada, es necesario crear cuentas de usuario. Este tutorial muestra los pasos para ejecutar pyWaPOR en un caso de prueba. En clase aprenderá más sobre estas fuentes de datos.
Antes de comenzar a ejecutar pyWaPOR, cree cuentas de usuario en cada uno de estos sitios web:
- NASA Earthdata portal para descargar data de MODIS, SRTM, CHIRPS, MERRA2, y VIIRS: https://urs.earthdata.nasa.gov
|
¡IMPORTANTE!
|
- Portal de Copernicus para descargar datos de Sentinel: https://dataspace.copernicus.eu/
- Portal Climate Data Store (CDS) para descargar datos de ERA5 y AgERA5: https://cds.climate.copernicus.eu
- Después de iniciar sesión, vaya a la página de su cuenta de usuario.
- En Clave API, copie y guarde la información de UID y Clave API
- Portal USGS Earthexplorer para descargar datos de Landsat: https://earthexplorer.usgs.gov
- Portal TerraScope para descargar datos de PROBA-V: https://viewer.terrascope.be
¡Asegúrese de guardar sus credenciales (nombre de usuario, dirección de correo electrónico de usuario, UID, clave API y contraseñas) en un lugar seguro!
2. Crear un script en Colab
Para crear un nuevo script con Colab, vaya primaro a https://colab.research.google.com/ y seleccione la pestaña "Google Drive". Haga clic en "New Notebook" para crear un nuevo cuaderno de Colab en su carpeta de Google Drive.
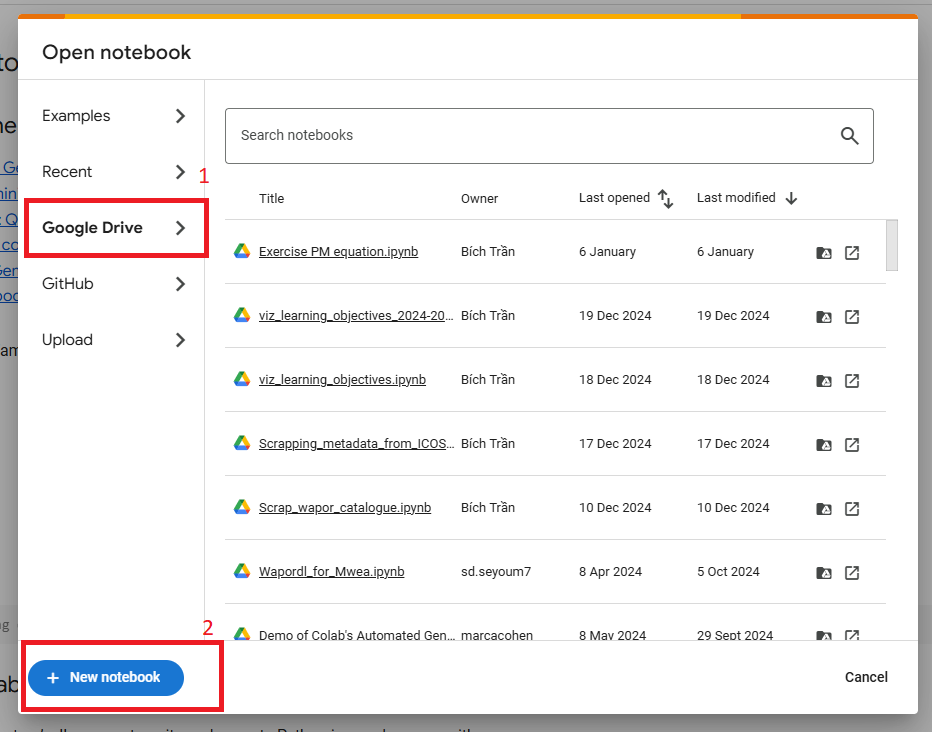
Cambie el nombre de este nuevo cuaderno haciendo doble clic en el título ubicado en la parte superior de la página (ver abajo). Por ejemplo, puede cambiarle el nombre a "pywapor_test_case_run0". Se recomienda utilizar siempre un nombre apropiado al cuaderno para facilitar el seguimiento al material y a los resultados.
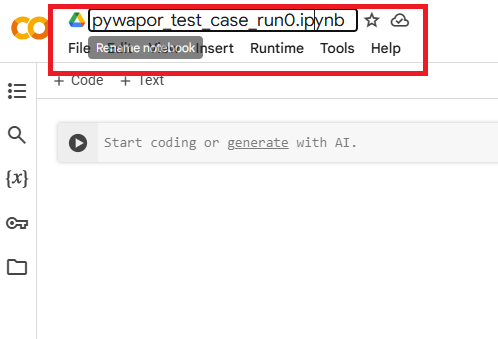
Puede agregar una celda con la palabra "Código" o "Texto". Use las celdas con la palabra "Texto" para explicar el contexto del código que va a agregar.
-
Las celdas de Markdown (celdas de texto) contienen texto formateado escrito en Markdown, un lenguaje de marcado liviano para crear texto formateado usando un editor de texto simple.
- Las celdas de código contienen código que será interpretado por el kernel (p. ej., Python, R, Julia, Octave/Matlab…). En este caso, estamos usando el kernel de Python.
En la siguiente página aprenderá a ejecutar pywapor para un caso de prueba usando Colab.
3. Ejecute el ejemplo de prueba PyWaPOR en Jupyter Notebook
En este paso creará nuevas celdas de código que ejecutarán cada paso en pywapor. Para el ejemplo de prueba, seleccionamos el área de Wad Helal, con la que debería estar familiarizado después de haber cursado el MOOC "Python para análisis geoespaciales utilizando datos de WaPOR".
En este ejercicio, se escribe el código para ejecutar este ejemplo. Copiará el código de cada paso, lo pegará en una nueva celda (de código), y lo ejecutará. Después de ejecutar cada celda, observe los resultados impresos. Después de cada paso, verifique que los resultados mostrados tengan sentido.
Para cada elemento numerado a continuación, cree una nueva celda de código en JupyterLab (atajo: B), copie el código en la celda y ejecútelo (atajo: MAYÚS + ENTER).
Paso 1: Instalar e importar el paquete de pywapor
!pip install pywapor import pywapor |
Este código instalará e importará el paquete pywapor al kernel de Python actual.
Paso 2: Configurar el proyecto para el caso de prueba
project_folder = r"Test_case" #Path to folder bb = [33.1479429498060583, 14.2657100971198449, 33.2874918465625242, 14.3487734799492763] # [xmin, ymin, xmax, ymax] #Wad_Helal period = ["2023-03-01", "2023-03-02"] # Set up a project. project = pywapor.Project(project_folder, bb, period) |
Este código crea una nueva carpeta de proyecto para el ejemplo, denominada "Test_case", define el cuadro delimitador (longitud mínima, latitud mínima, longitud máxima, latitud máxima) del caso (es decir, Wad Helal) y define el período de tiempo durante el cual se ejecutará el modelo. Para este caso , ejecutaremos el modelo sólo durante 2 días como ejemplo (es decir, los dos primeros días de marzo de 2023).
Paso 3: Configurar el conjunto de datos de entrada
summary = { '_ENHANCE_': {"lst": ["pywapor.enhancers.dms.thermal_sharpener.sharpen"],}, '_EXAMPLE_': 'SENTINEL2.S2MSI2A_R20m', '_WHITTAKER_': {'SENTINEL2.S2MSI2A_R20m':{'method':'linear'}, 'VIIRSL1.VNP02IMG':{'method':'linear'}, }, 'elevation': {'COPERNICUS.GLO30'}, 'meteorological': {'GEOS5.inst3_2d_asm_Nx'}, 'optical': {'SENTINEL2.S2MSI2A_R20m'}, 'precipitation': {'CHIRPS.P05'}, 'soil moisture': {'FILE:{folder}{sep}se_root_out*.nc'}, 'solar radiation': {'MERRA2.M2T1NXRAD.5.12.4'}, 'statics': {'STATICS.WaPOR3'}, 'thermal': {'VIIRSL1.VNP02IMG'}, } project.load_configuration(summary = summary) |
Este código configurará el conjunto de datos de entrada para este proyecto de ejemplo. Toda la información sobre las fuentes de los conjuntos de datos de entrada y los métodos para preprocesar los datos de entrada está definida por la variable 'summary'.
También hay opciones para ejecutar pywapor con el conjunto de entradas predeterminado que se utiliza para los productos de datos de WaPOR. En clase, aprenderá más sobre las diferentes configuraciones predeterminadas y personalizadas de pywapor y lo que significa cada línea en este código.
Paso 4: Configurar las credenciales para descargar datos
project.set_passwords() |
Este código le solicitará que ingrese las cuentas de usuario y las contraseñas que se requieren para descargar los conjuntos de datos de entrada configurados. Use la cuenta de usuario y la contraseña que creó anteriormente (sección Crear cuentas de usuario). Para este ejemplo, deberá ingresar el nombre de usuario y la contraseña de la cuenta de NASA Earthdata, y la dirección de correo electrónico y la contraseña de la cuenta de Copernicus. Se utilizarán otras cuentas para ejecutar pywapor con otros conjuntos de datos.
Paso 5: Descargar datos
datasets = project.download_data() |
Este código iniciará el proceso de descarga de datos de entrada para pywapor. Dado que está ejecutando el Notebook en Google Colab, los datos se descargarán en su máquina virtual de Google Colab. El tiempo que lleva descargar los datos depende del período y del área (y se indica que, para el área de Wad Helal, se necesitan menos de 30 minutos para descargar 2 días de datos).
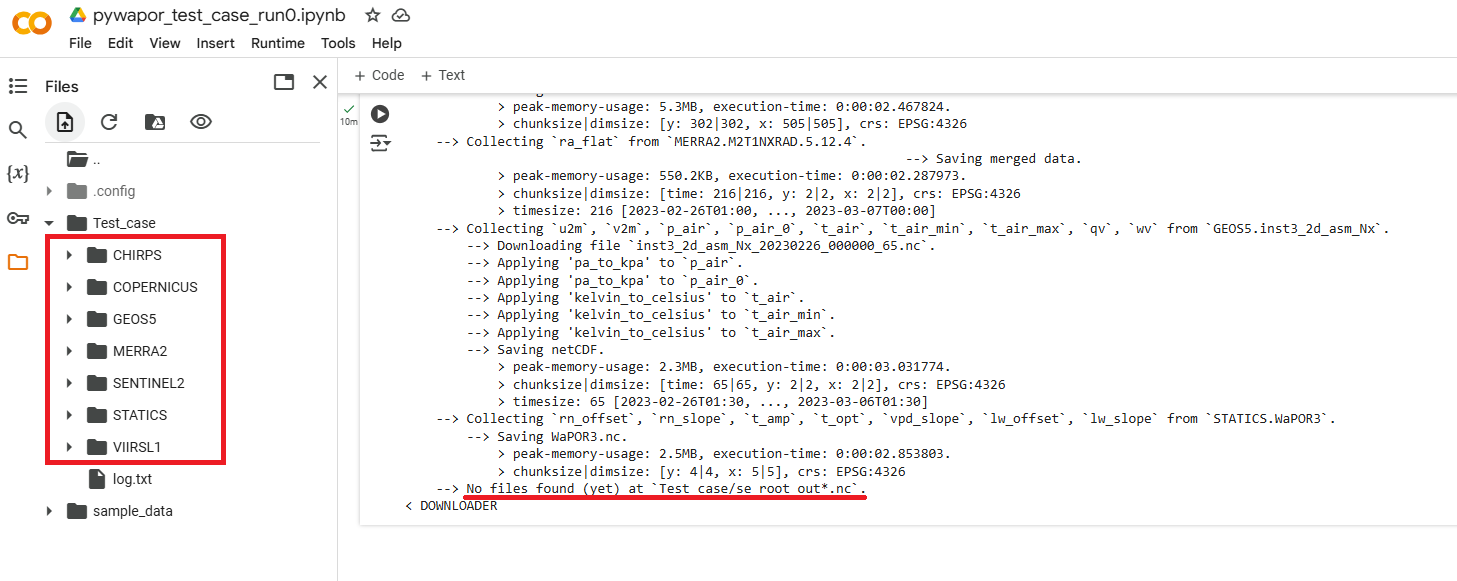
Después de este paso, si todos los datos se descargaron correctamente, debería encontrar estas carpetas de entrada en el panel Archivos a la izquierda (haga clic en el ícono de carpeta ![]() para abrir este panel):
para abrir este panel):
Notas:
- No es necesario descargar el archivo se_root_out*.nc en este paso, porque estamos usando un modelo para calcular la humedad del suelo en la zona de raíces. Por lo tanto, puede ignorar la advertencia, que traduce: "No se encontraron archivos (aún) en 'Test_case/se_root_out*.nc'".
- Si no se encuentra ningún otro archivo o se muestran mensajes de error en este paso, significa que las entradas requeridas no se han descargado por completo (por ejemplo, debido a errores de conexión o del servidor). Deberá volver a ejecutar este paso.
Paso 6: Preprocesar los datos de entrada para el modelo de humedad del suelo en la zona de raíces
se_root_in = project.run_pre_se_root() |
Este código preprocesará los datos descargados en un formato compatible con el modelo se_root.
Si este paso se completa correctamente, debería encontrar el archivo se_root_in.nc en la carpeta del proyecto:
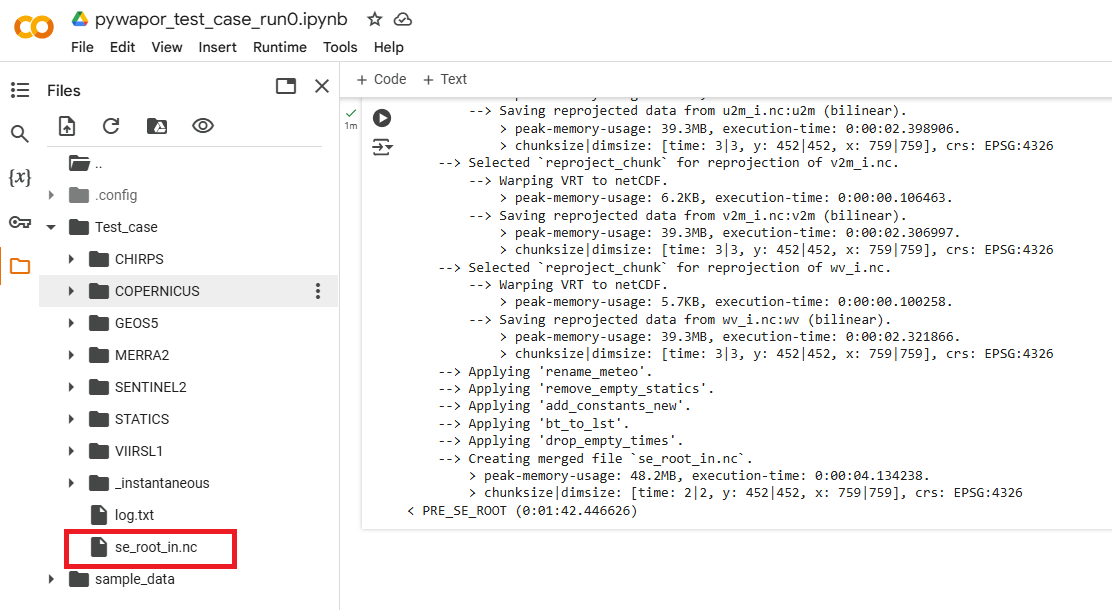
Paso 7: Ejecutar el modelo de humedad del suelo de la zona de raíces
se_root = project.run_se_root() |
Este código ejecutará el módulo se_root para calcular la humedad del suelo en la zona de raíces, que es una entrada para calcular la evapotranspiración.
Si este paso se completa correctamente, debería encontrar el archivo se_root_out.nc en la carpeta del proyecto:
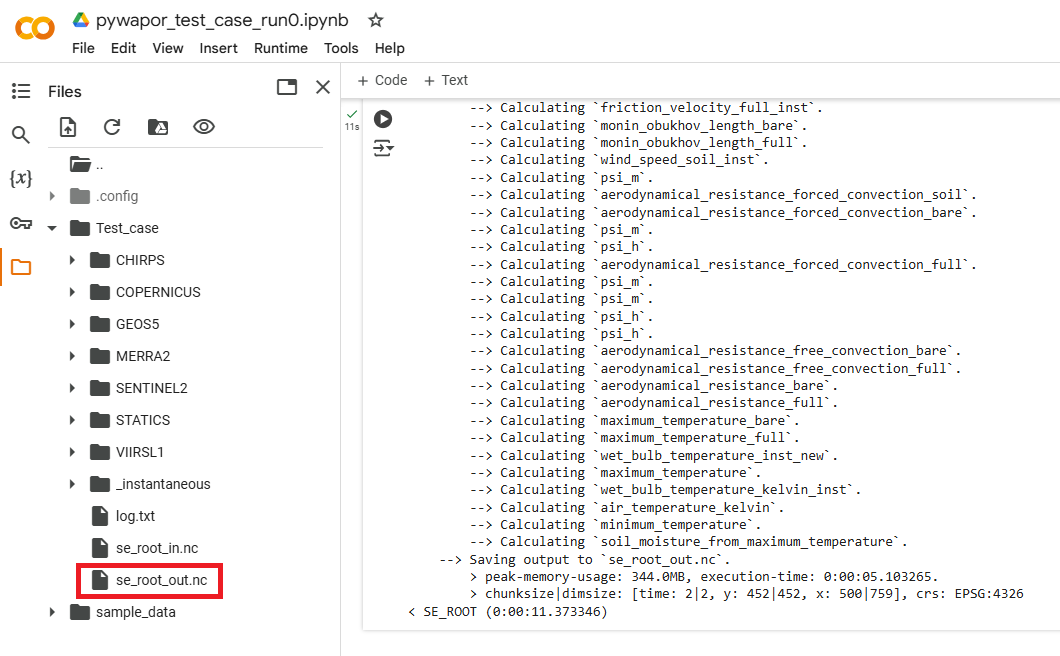
Paso 8: Preprocesar los datos de entrada para el modelo etlook
et_look_in = project.run_pre_et_look() |
Este código preprocesará los datos descargados y se_root_out.nc en un formato compatible con el modelo et_look.
Si este paso se completa correctamente, debería encontrar el archivo et_look_in.nc en la carpeta del proyecto:
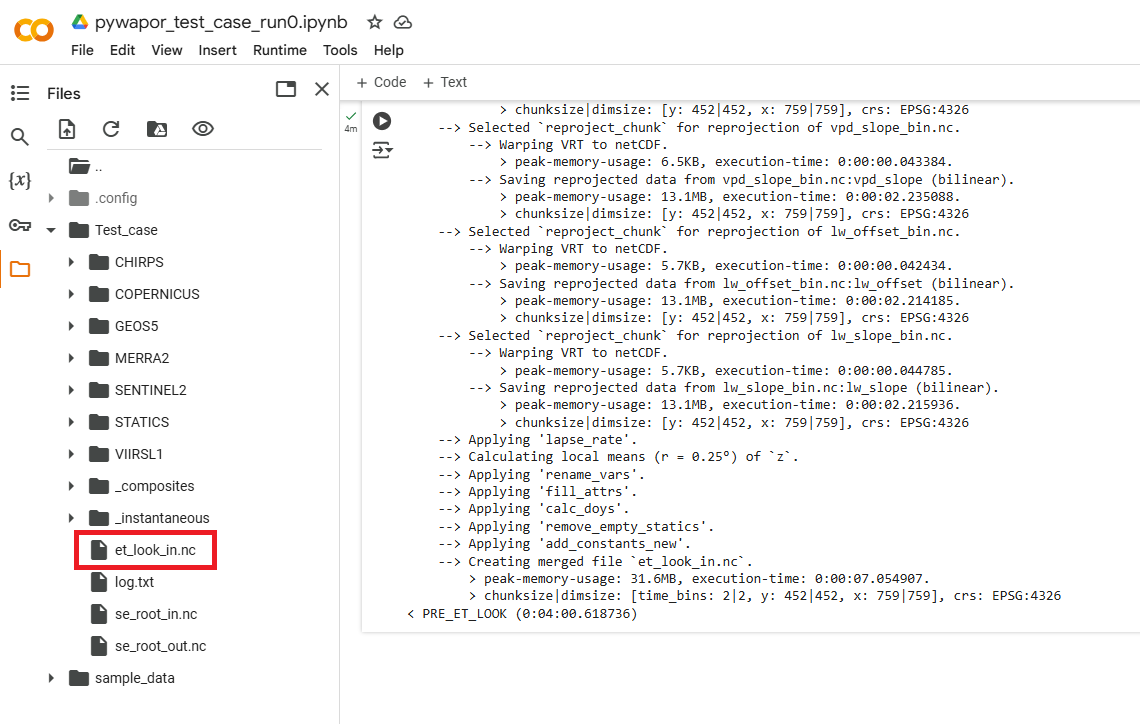
Paso 9: Ejecutar el modelo etlook
et_look = project.run_et_look() |
Este código ejecutará el módulo et_look para calcular la evaporación, la transpiración, la intercepción y la producción primaria neta.
Si este paso se completa correctamente, debería encontrar el archivo et_look_out.nc en la carpeta del proyecto:
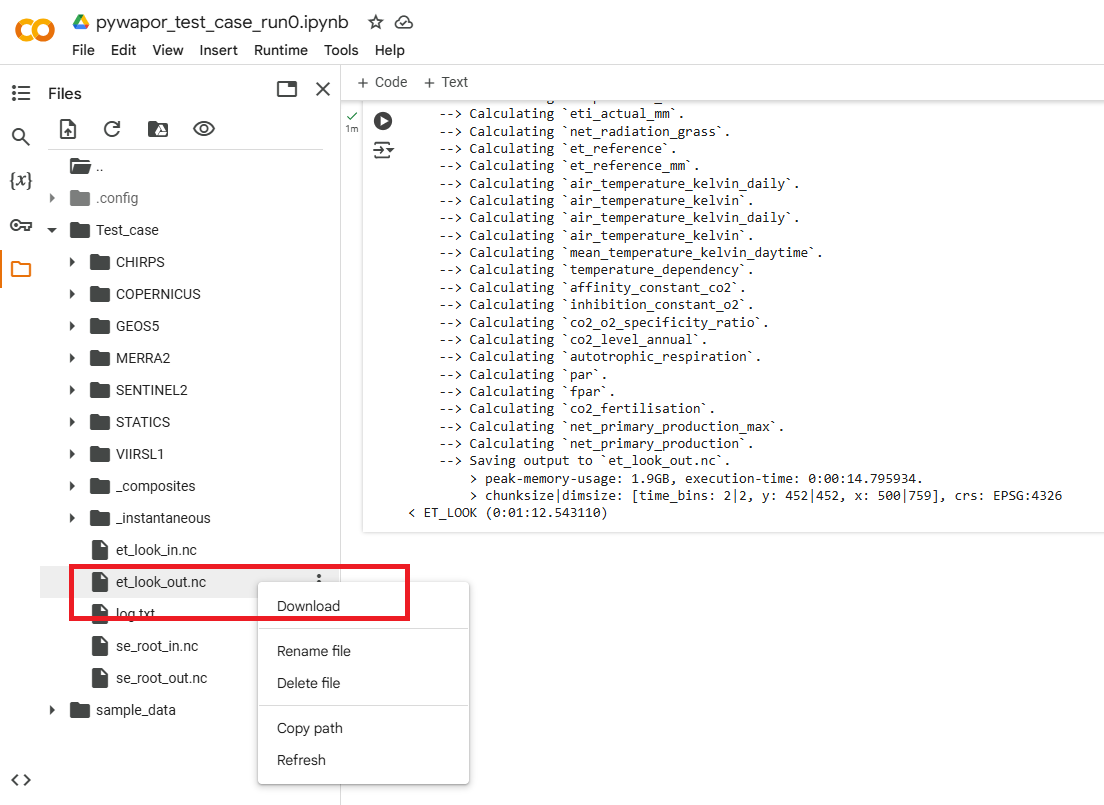
Al finalizar este ejercicio, deberá poder crear un cuaderno Jupyter como este cuaderno de ejemplo, ejecutarlo y obtener el archivo de salida de pywapor et_look_out.nc. A continuación, investigaremos este archivo de salida y lo analizaremos en clase.
4. Investigando los resultados de pyWaPOR
Una vez que termine de ejecutar el script pyWaPOR, tendrá un archivo llamado et_look_out.nc en la carpeta del proyecto.
Este es un archivo de tipo NetCDF que contiene todos los archivos de salida. Los archivos NetCDF tienen la ventaja de comprimir los datos y son fáciles de usar para programadores. Descargue el archivo de salida a su computadora (esto es porque este archivo se sobrescribirá cuando ejecute pyWaPOR nuevamente). Abra el archivo en QGIS siguiendo el "Tutorial 4: NetCDF en QGIS".
Explore los resultados, los cuales discutiremos en clase. Piense en lo siguiente:
- ¿Qué tipo de capas de salida se incluyen en el archivo de salida?
- ¿Por qué los datos no cubren todo el cuadro delimitador?
Prepare cualquier otra pregunta o inquietud que tenga y pregúntela en clase.