Tutorial 3 (ES): Configuración de pyWaPOR para su propio caso de estudio
| Site: | IHE DELFT OPENCOURSEWARE |
| Course: | PyWaPOR OpenCourseWare |
| Book: | Tutorial 3 (ES): Configuración de pyWaPOR para su propio caso de estudio |
| Printed by: | Guest user |
| Date: | Friday, 26 December 2025, 6:53 PM |
Description
En este tutorial, creará un cuaderno (Jupyter Notebook) para ejecutar pyWaPOR para su propio caso de estudio en su computadora local. De manera similar al ejemplo de prueba, este cuaderno debe contener todas las celdas de código para configurar el proyecto, configurar el conjunto de datos de entrada, configurar cuentas, descargar datos, ejecutar el modelo de humedad del suelo de la zona de raíces (SERoot) y ejecutar el modelo ETLook. Sin embargo, la diferencia es que usted creará y ejecutará este cuaderno en su computadora local.
1. Cree un nuevo Jupyter Notebook para su proyecto
Recuerde que en este tutorial utilizamos la palabra 'entorno' para referirnos al 'environment' de Python.
Después de crear un entorno de Python con pywapor y jupyterlab siguiendo el paso del Tutorial 2: Instalación de Jupyter Notebook en su computadora local, ahora puede abrir JupyterLab en su máquina. En este paso, creará un nuevo Jupyter Notebook para su propio caso:
- Primero, abra el símbolo del sistema de Miniforge y ejecute la siguiente línea de comando:
mamba activate pywapor_env
- Luego, cambie su carpeta de trabajo. Recomendamos crear una carpeta dedicada para cada nuevo proyecto en una unidad donde tenga suficiente almacenamiento disponible (por ejemplo, D:\\pywapor). Si está en la unidad C:, primero deberá cambiar a la unidad D: usando el siguiente comando:
D:
cd D:\\pywapor
- Ejecute el siguiente comando para iniciar JupyterLab:
jupyter lab
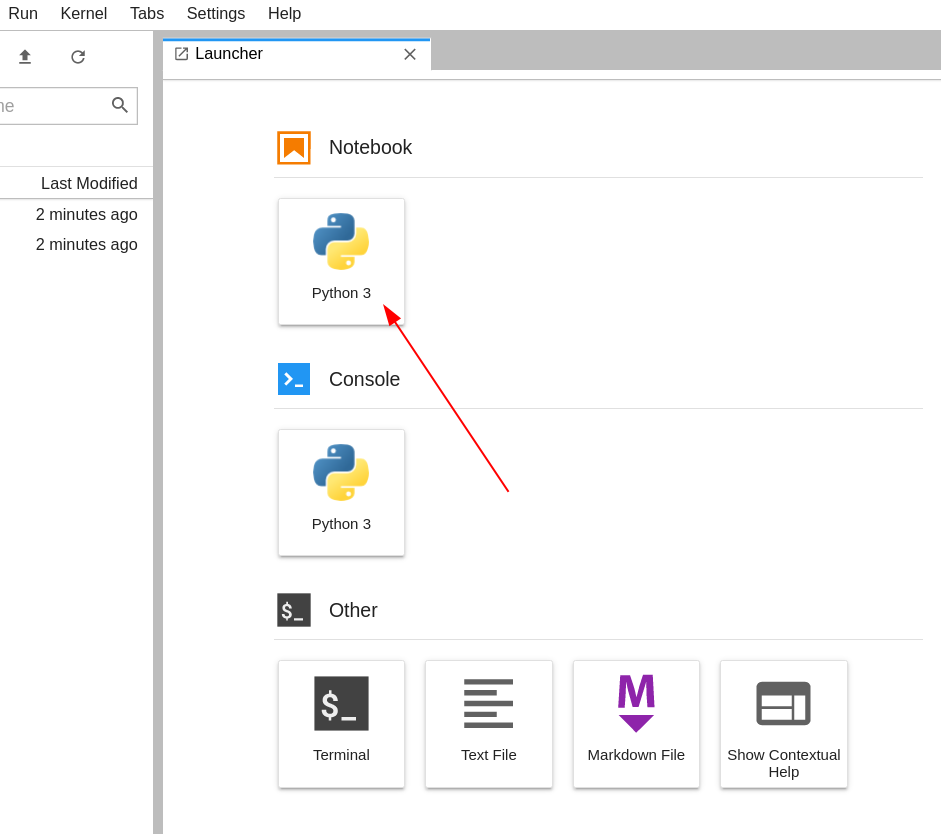
Una vez que la interfaz de JupyterLab esté abierta en su navegador web, haga clic en el mosaico "Python" debajo de "Notebook" en la pestaña "Launcher" para crear un nuevo notebook.
(© Copyright CodeRefinery team)
Verá un nuevo cuaderno llamado "Untitled.ipynb". Para cambiar el nombre del cuaderno, haga clic derecho en la pestaña y seleccione "Cambiar nombre del cuaderno..."
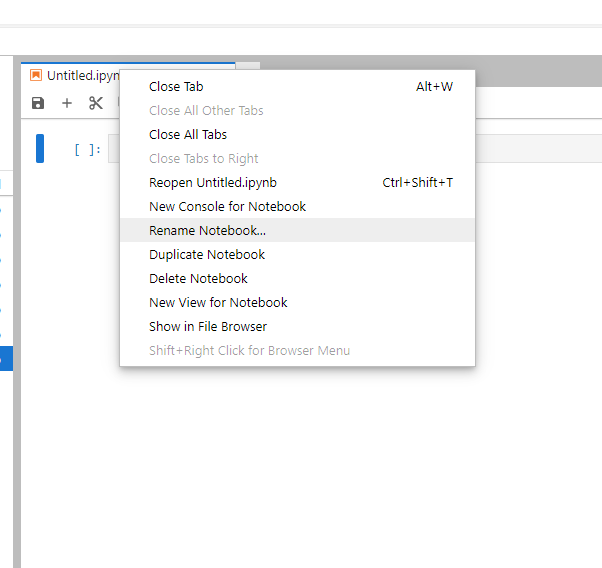
Ingrese el nombre de este nuevo cuaderno (por ejemplo, "Ejecutar pywapor case study.ipynb") y haga clic en "Cambiar nombre".
En la primera celda de código, importe el paquete pywapor ejecutando este código:
import pywapor
2. Configuración del proyecto PyWaPOR
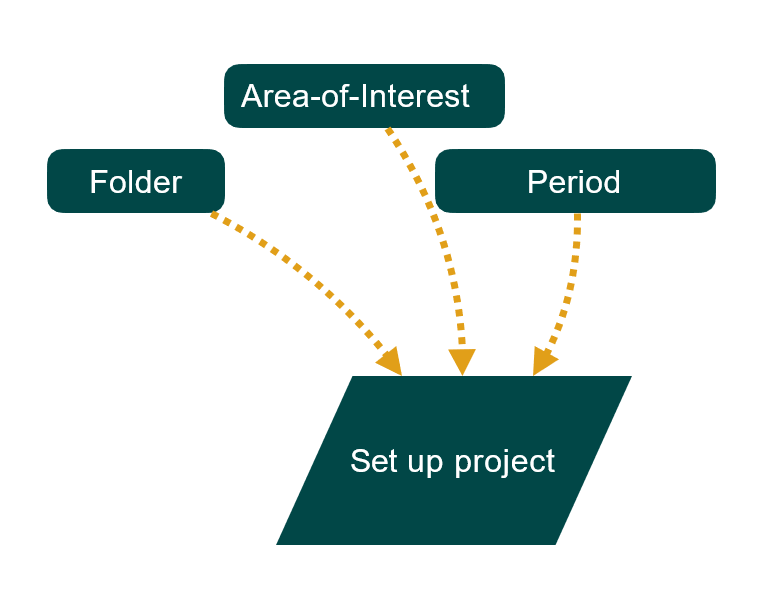
Para configurar pyWaPOR para su propio caso de estudio, necesitará la siguiente información:
- carpeta del proyecto
- cuadro delimitador del área de interés (AoI)
- Período de estudio (que suele ser el inicio y el final de la temporada de cultivo).
Cree una nueva celda de código con los parámetros de su nuevo proyecto usando la siguiente plantilla (recuerde que el símbolo # sirve para hacer comentarios o anotaciones):
project_folder = r"D:\\pywapor\\Case_study" # Definición de la ruta de la carpeta del proyecto bb = [xmin, ymin, xmax, ymax] # Cuadro delimitador del área del proyecto period = ["YYYY-MM-DD", "YYYY-MM-DD"] # Set up a project project = pywapor.Project(project_folder, bb, period)
2.1. Carpeta
Reemplace el valor de project_folder en el código anterior con la ruta absoluta a la carpeta de su proyecto. Dado que ha iniciado Jupyter Notebook en su carpeta de trabajo (por ejemplo, D:\\pywapor), si usa una ruta relativa (es decir, "Case_study"), la función pywapor.Project creará una nueva carpeta en su carpeta de trabajo llamada "Case_study" (por ejemplo, D:\\pywapor\Case_study).
Nota:
- Al cambiar el área de interés, el período o la configuración del proyecto, es mejor crear una nueva carpeta de proyecto por separado
2.2. Área de interés
Defina el valor de la variable bb (bounding box, o cuadro delimitador) en el código anterior con una lista que contenga los valores de longitud mínima, latitud mínima, longitud máxima y latitud máxima de su área de estudio. Si tiene un shapefile de su área de estudio (con el sistema de referencia de coordenadas EPSG:4326), el cuadro delimitador de su área de estudio se puede encontrar observando la propiedad "extensión" del shapefile. Para ello, abra el shapefile en QGIS. Luego, haga clic derecho en la capa shapefile en el panel Capas y seleccione “Propiedades”. En la pestaña 'Información', copie las coordenadas de la 'Extensión'. Vea el ejemplo a continuación.
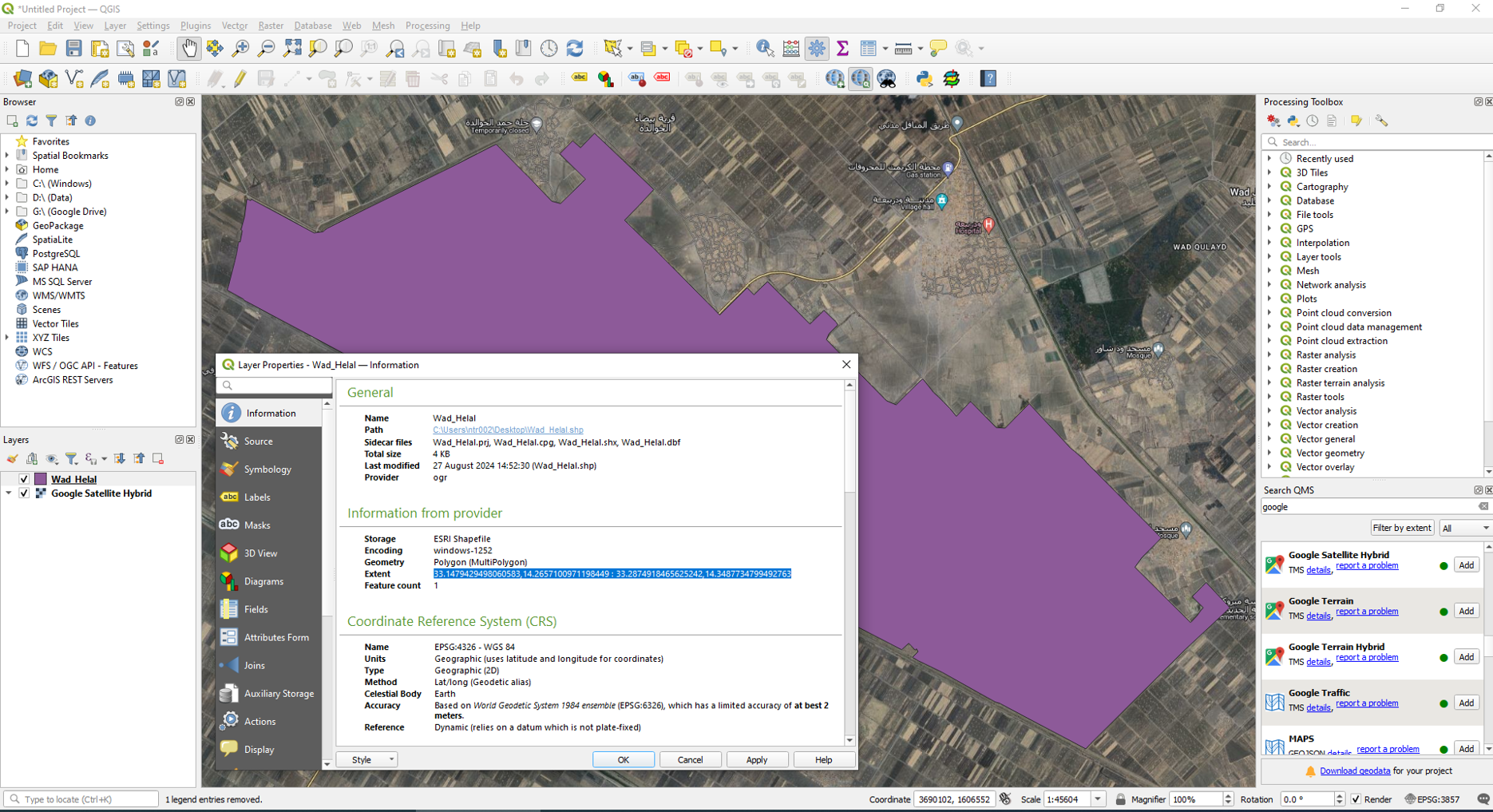
Pegue las coordenadas copiadas en la celda de código en Jupyter Notebook, y asegúrese de cambiar el formato de xmin, ymin: xmax, ymax a [xmin, ymin, xmax, ymax]
2.3. Período
Reemplace el valor del period en el código anterior con una lista de fechas de inicio y fecha de finalización de su período de estudio en el formato ["AAAA-MM-DD", "AAAA-MM-DD"].
Tenga en cuenta que seleccionar un período prolongado (desde unos meses hasta más de un año) podría sobrecargar la memoria de procesamiento de su computadora, en particular si su área es muy grande. Como ejecutamos el código en una computadora portátil normal (8 GB de RAM), sólo podemos descargar y procesar un mes de datos. Seleccione un mes en el medio de la temporada de cultivo y agregue 5 días antes y 5 días después. Esto es con el fin de tener un período de reserva para la interpolación de fechas con datos faltantes.
Por ejemplo, si su temporada de cultivo es del 01-10-2020 al 30-04-2021, seleccione el mes intermedio del 01-01-2021 al 31-01-2021. Luego agregue 5 días antes y después de este período. El valor de period será entonces: ["2020-12-25", "2021-02-05"].
Una vez configurado el proyecto con la información requerida, ejecute el código.
3. Descarga de datos de entrada
Asegúrese de tener las credenciales y passwords que creó anteriormente a la mano.
Después de configurar el proyecto, el siguiente paso es configurar el conjunto de datos de entrada y descargarlos. Copie el código de ejemplo que aparece a continuación en su Jupyter Notebook y ejecute las celdas de código.
- Configuración del conjunto de datos de entrada:
summary = { 'elevation': {'COPERNICUS.GLO30'}, 'meteorological': {'GEOS5.inst3_2d_asm_Nx'}, 'optical': {'SENTINEL2.S2MSI2A_R20m'}, 'precipitation': {'CHIRPS.P05'}, 'solar radiation': {'MERRA2.M2T1NXRAD.5.12.4'},
'statics': {'STATICS.WaPOR3'}, 'thermal': {'VIIRSL1.VNP02IMG'},
'soil moisture': {'FILE:{folder}{sep}se_root_out*.nc'},
'_ENHANCE_': {"bt": ["pywapor.enhancers.dms.thermal_sharpener.sharpen"],}, '_EXAMPLE_': 'SENTINEL2.S2MSI2A_R20m', '_WHITTAKER_': {'SENTINEL2.S2MSI2A_R20m':{'method':'linear'}, 'VIIRSL1.VNP02IMG':{'method':'linear'}, }, } project.load_configuration(summary = summary)
- Puede configurar un conjunto personalizado de fuentes de datos de entrada. Seleccione la fuente y el código del producto en:
https://www.fao.org/aquastat/py-wapor/data_sources.html
-
- Asegúrese de haber completado todas las categorías (es decir, elevación, meteorología, óptica, precipitación, radiación solar, estadísticas y térmica). Para la categoría "humedad del suelo", utilizaremos la salida del modelo SERoot. Puede seleccionar más de una fuente de datos de entrada. Si lo hace, el tiempo de descarga y procesamiento de los datos será mayor.
- Por ejemplo, si desea utilizar datos térmicos MODIS en lugar de VIIRS, el ejemplo anterior se puede modificar de la siguiente manera:
summary = { 'elevation': {'COPERNICUS.GLO30'}, 'meteorological': {'GEOS5.inst3_2d_asm_Nx'}, 'optical': {'SENTINEL2.S2MSI2A_R20m'}, 'precipitation': {'CHIRPS.P05'}, 'solar radiation': {'MERRA2.M2T1NXRAD.5.12.4'},
'statics': {'STATICS.WaPOR3'}, 'thermal': {'MODIS.MYD11A1.061','MODIS.MOD11A1.061'}
'soil moisture': {'FILE:{folder}{sep}se_root_out*.nc'},
'_ENHANCE_': {"lst": ["pywapor.enhancers.dms.thermal_sharpener.sharpen"],}, '_EXAMPLE_': 'SENTINEL2.S2MSI2A_R20m', '_WHITTAKER_': {'SENTINEL2.S2MSI2A_R20m':{'method':'linear'}, 'MODIS.MYD11A1.061':{'method':'linear'},
'MODIS.MOD11A1.061':{'method':'linear'}, }, } project.load_configuration(summary = summary)
- Configurar las credenciales de la cuenta para descargar datos
project.set_passwords()
-
- Dependiendo de la fuente de datos y el producto seleccionados, el código le solicitará que ingrese las cuentas de usuario y las contraseñas que se requieren para descargar los conjuntos de datos de entrada configurados.
- Descargar datos
datasets = project.download_data()
Este código iniciará el proceso de descarga de datos de entrada para pywapor. Cuando Python esté ejecutando la celda, asegúrese de tener conexión a Internet.
Cuando ejecute pywapor para su propio caso de estudio, el paso de descarga puede demorar más debido a interrupciones del servidor u otras razones; es posible que no todos los datos se descarguen. Al ejecutar el código, se crea un registro en el que se puede verificar si hay advertencias de datos que no se descargaron por completo. En este registro, entre las etiquetas > DOWNLOADER y < DOWNLOADER, no se debería haber mencionado ninguna advertencia, excepto por el se_root_out.nc faltante, que se creará en el siguiente paso.
Notas:
Debido a interrupciones del servidor e Internet, es posible que vea algunas advertencias en el registro impreso que indiquen que pywapor puede continuar sin ciertos datos de entrada. Si esto sucede, deberá volver a ejecutar el paso de descarga. Para ello, deberá reiniciar el kernel seleccionando la pestaña 'Kernel' > 'Reiniciar kernel'. Elimine los archivos dañados (de tamaño sospechosamente bajo) en las carpetas de datos de entrada. Luego, vuelva a ejecutar todas las celdas de código.
4. Ejecutar los modelos SERoot y ETLook
Una vez que se hayan recopilado todos los datos correctamente, la única entrada que falta es la humedad del suelo de la zona de raíces. Copie el siguiente código en su Jupyter Notebook y ejecútelo.
- Ejecute el modelo de humedad del suelo de la zona de raíces
se_root_in = project.run_pre_se_root() se_root = project.run_se_root(chunks = {"time": 1, "x": 500, "y": 500})
Este código preprocesará los datos de entrada y ejecutará el módulo se_root para calcular la humedad del suelo de la zona de raíces, que es una entrada para calcular la evapotranspiración.
- Ejecute el modelo etlook
et_look_in = project.run_pre_et_look() et_look = project.run_et_look(chunks = {"time_bins": 1, "x": 500, "y": 500})
Este código preprocesará los datos de entrada y ejecutará el módulo et_look para calcular la evaporación, la transpiración, la intercepción y la producción primaria neta.
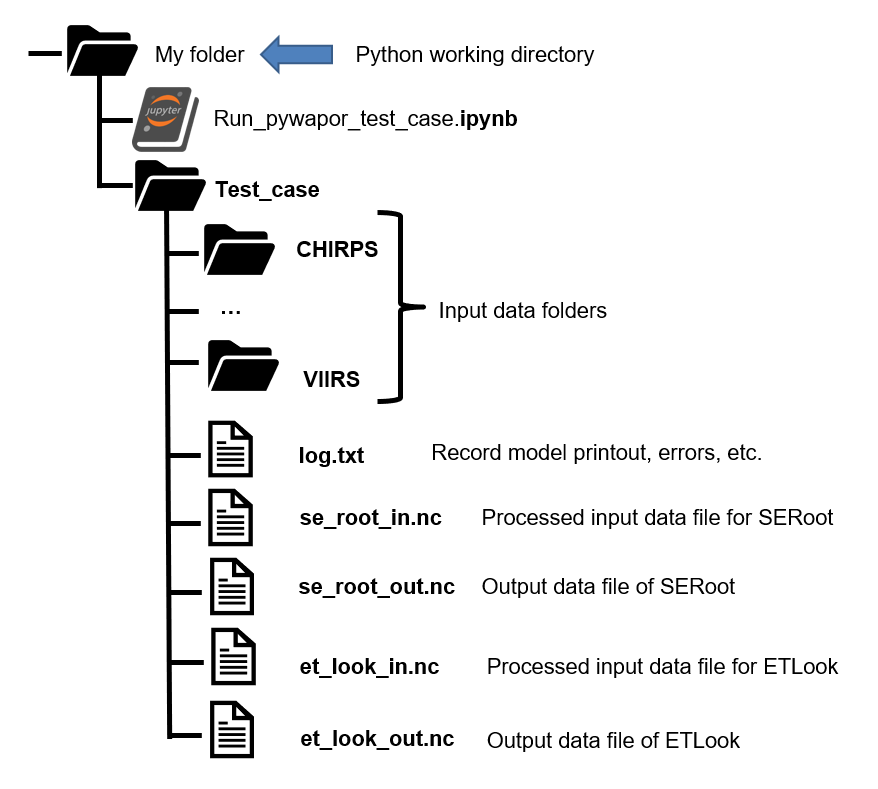
Al ejecutar cada celda, observe los mensajes impresos en la salida. Al final de este ejercicio, debería tener el archivo de salida et_look_out.nc, entre otros archivos, en la carpeta del proyecto: